
💙 들어가며
중복된 값을 제거해주는 DISTINCT와 행번호 ROWNUM에 대해서 알아보고,
ROWNUM을 뽑기 위해서 꼭 알아야 하는 SUB쿼리의 개념에 대해서 배워보자.
✏️ 학습내용 정리
#DISTINCT
DISTINCT는 특정 열에서 중복된 값을 제거해서 출력하고 싶을 때 사용할 수 있는 녀석이다.
💡 DISTINCT
1. 중복값을 제거해주는 역할을 한다.
2. 단, DISTINCT는 오로지 하나의 컬럼을 출력할 때만 쓰일 수 있다.
두 개 이상의 컬럼을 출력할 때는 사용할 수 없다.
DISTINCT를 사용하기 전에는 이렇게 중복값이 있었던 것이

DISTINCT를 적용함으로써 사라지는 것을 볼 수 있다.

단일 열을 출력할 때 중복값을 제거하기 위해서 요긴하게 사용될 수 있겠다.
#ROWNUM
ROWNUM은 우리가 따로 만들어준 값이 아니지만 결과집합에서 행이 생성됨에 따라 자동으로 붙는 번호라고 한다.
💡 ROWNUM
1. 결과집합이 만들어질 때 자동으로 만들어지는 행번호이다.
SELECT 구문에서 WHERE절이 실행될 때 쯤 만들어진다.
2. 페이징 작업을 할 때 사용된다.
ROWNUM을 가지고 특별한 추가 조건 없이 상위부터 N개씩 출력하는 방식으로 페이징한다.
3. SUB쿼리가 있어야지만 ROWNUM을 제대로 뽑을 수 있다.
ROWNUM은 다루기 까다로운 녀석이다.. WHERE절에서 1부터 뽑아오는 것이 아닌 경우에는 오류가 난다.

이유는 ROWNUM이 쌓이지 않았기 때문이다.
WHERE이 실행되면서 하나씩 조건을 걸러서 데이터를 차곡차곡 쌓으며 ROWNUM을 자동으로 붙이게 되는데,
(즉, 데이터가 먼저 쌓여야지만 ROWNUM이 붙게 됨)
무조건 1부터 시작할 수 밖에 없는 ROWNUM을 6이상인 경우에만 뽑아오라면서 데이터에 제한을 걸기 때문이다.
(조건에서 ROWNUM을 먼저 찾고, 조건에 맞는 데이터를 뽑으라고 함)
선후관계 모순이다. 처음부터 ROWNUM이 6인 데이터는 없다.
데이터가 있어야 ROWNUM이 붙고, 데이터가 쌓여야 ROWNUM이 쌓이는데, 어떻게 처음부터 행번호가 6번인 데이터가 있을 수 있다는 말인가.. 해당되는 데이터가 없으니 애초에 쌓일 데이터도 없고 ROWNUM도 붙을 수가 없다.
#SUB쿼리
그러면 ROWNUM은 항상 1부터 뽑아야만 하는 것일까? 그렇다면 어떻게 페이징을 한다는 말일까?
바로 SELECT문에서 가장 먼저 실행되는 FROM을 활용하면 오류가 나는 문제를 해결할 수 있다.
FROM뒤에는 꼭 테이블만 올 수 있는 것이 아니다. 격자형 데이터가 올 수 있다. 그래서 RESULTSET이 올 수 있다.
ROWNUM은 RESULTSET(RS)이 만들어질 때 최종적으로 만들어지는 녀석이기 때문에 FROM뒤에 ROWNUM을 포함한 RS를 미리 만들어서 그 RS를 불러오면 RS의 ROWNUM을 WHERE절로 SELECT해서 사용할 수 있다.
이때 FROM뒤에 오는 격자형 데이터(RS)를 만들기 위해 사용하는 쿼리를 쿼리 안에 쿼리라고 해서 SUB쿼리라고 한다.
SELECT * FROM (SELECT * FROM MEMBER) 에서 소괄호()안에 들어가는 쿼리

#ROWNUM 뽑을 때 주의할 점
그리고 ROWNUM과 모든 열(*)을 함께 SELECT할 때 주의할 점이 있다.
*은 이미 모든 것이라는 의미를 가지고 있기 때문에 다른 열과 함께 올 수 없다.
따라서 NOTICE.*과 같이 TABLE명을 밝혀서 적어주어야 한다.

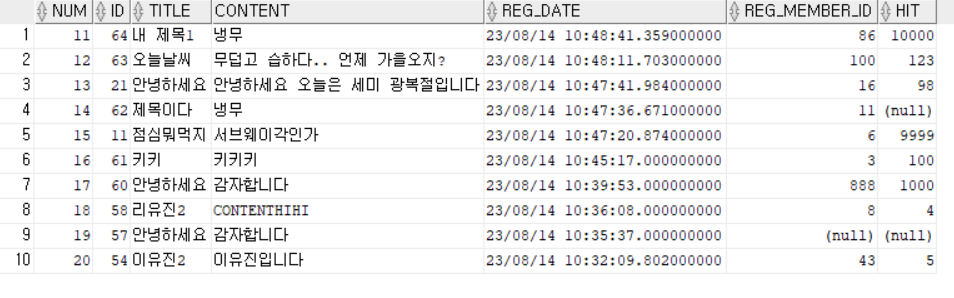
최신 등록일자 순으로 정렬한 결과집합을 만든 뒤에 만들어진 결과집합에 ROWNUM을 붙이고,
그 다음에 ROWNUM이 11~20사이인 값들만 뽑아보자.
(여기서 주의할 점은 SELECT문의 실행 순서이다.)
💡 등록일자가 NULL이 아닌 것들 중에 최신 등록일자 순으로 ROWNUM을 순서대로 매겨서 출력해보자.
💯 ROWNUM을 언제 생성해야 하는지 생각해보자.
SELECT * FROM
--2. 그 뒤에 ROWNUM을 붙여주고 (정렬된 순서대로 ROWNUM이 붙게)
(SELECT ROWNUM NUM, N.* FROM
--1. 등록일이 NULL이 아니면서 최신순으로 REG_DATE 역정렬을 하고
(
SELECT * FROM NOTICE WHERE REG_DATE IS NOT NULL ORDER BY REG_DATE DESC
)
N)
--3. 그 다음에 필터링을 한다.
WHERE NUM BETWEEN 11 AND 20;⭕ 출력결과:
MAIN쿼리 1개와 SUB쿼리를 2개를 사용했다. (총 3개)
---------------------------------------------------------------------------
이유: ORDER BY와 ROWNUM 때문이다.
ROWNUM은 WHERE절이 실행될 때 쯔음 만들어지기 때문에 ORDER BY보다 먼저 생성되는데,
이 둘을 분리하지 않고 하나의 쿼리에서 ORDER BY까지 수행해버리면 기껏 만든 ROWNUM의 번호가 꼬이게 된다.
따라서, ORDER BY문장을 먼저 SUB1로 실행하고
그것에 ROWNUM을 붙인 SUB2를 한 번 더 실행하고
그 위에서 WHERE절을 이용해서 SELECT하는 형식으로 접근해야 한다.
---------------------------------------------------------------------------
풀이:
첫번째 SUB쿼리에서는 ROWNUM을 포함해서 만들지 않았다.
ROWNUN은 WHERE구절 즈음 생성되기 때문에
ROWNUM이 만들어진 상태에서 ORDER BY가 되면 ROWNUM의 순서가 뒤죽박죽 되기 때문이다.
그래서 두번째 SUB쿼리에서 정렬된 RESULTSET을 가지고 ROWNUM을 붙여주었다.
그리고 마지막 MAIN쿼리에서 ROWNUM이 11~20사이인 것들만을 출력했다.
#번외: 튜닝(ID로 정렬했을 때는 왜 ROWNUM이 꼬이지 않을까?)
위에서 SELECT로 ROWNUM을 뽑으면서 ORDER BY를 하면 ROWNUM의 순서가 꼬이는 것을 확인했다.
그런데 이상하게 ID는 정렬하면서 ROWNUM을 SELECT해도 꼬이지 않는다.
이유는 ID가 ROWNUM이 생성될 때 기준이 되는 디폴트값이기 때문이다.
ROWNUM은 별다른 정렬이 없으면 ID로 자동 정렬된다.
때문에 ID는 ORDER BY를 해도 실질적으로 내부에서는 따로 정렬되는 것이 없다.

실제 튜닝될 때를 확인해보아도 ID는 따로 정렬작업이 없다.
왜냐하면 ID그 자체가 Primary Key이기 때문에 자체 색인을 가지고 있기 때문이다.
비교하기 위해서 REG_DATE로 재정렬하면 SORT작업이 별도로 들어가는 것을 볼 수 있다.

ID로 정렬하면 SORT작업이 들어가지 않는다.

때문에 이런 점들을 고려해서 data를 쿼리하면 데이터를 다룰 때 소요되는 시간을 훨씬 줄일 수 있다.
데이터의 양이나 Query해야 하는 columns의 수가 많아진다면 이런 것들을 고려해서 튜닝을 할 필요가 있겠다.
#WHERE절에도 SUB쿼리를 쓸 수 있다.
FROM뿐만 아니라 WHERE절에도 SUB쿼리를 쓸 수 있다. 다음과 같은 상황을 생각해보자.
평균 나이와 현재 나이를 비교해서 특정 조건에 해당하는 사람만 뽑고 싶을 때,
WHERE절에서는 집계함수를 사용할 수 없기 때문에 난감한 상황이 발생한다.
그럴 때 SUB쿼리를 이용해서 처리할 수 있다.
회원의 평균나이보다 나이가 많은 회원들을 검색해볼 때 다음과 같이 SUB쿼리를 이용할 수 있다.
💡 평균나이를 집계해서 WHERE절에서 사용해보자.
--나이가 30보다 많은 회원들만 검색해주세요.
SELECT * FROM MEMBER WHERE AGE >30 ORDER BY AGE DESC;
--회원의 평균 나이보다 나이가 많은 회원들을 검색해주세요.
SELECT * FROM MEMBER WHERE AGE > (SELECT AVG(AGE) FROM MEMBER) ORDER BY AGE DESC;
WHERE문에서는 집계함수를 사용하지 못하고, 단일 값으로만 비교할 수 있는데
이 단일 값은 집계함수를 사용해야지만 나오는 상수이다. 그래서 계산값을 뽑기 위해 SUB쿼리를 계산식처럼 사용했다.
마치 30이 들어가야 할 자리에 SUB쿼리로 집계를 하는 식이 들어가는 것과 같다.

WHERE절에서 SUB쿼리를 이용해서 계산을 할 수 있다는 것을 기억해두면 잘 활용할 수 있을 것 같다.
#ANY와 ALL
값이 여러개 올 때 WHERE에서 비교할 수 있는 방법중에 any와 all이 있다.
💡 ANY와 ALL
1. 반드시 비교연산자와 같이 쓰인다.
2. 차이점
🔎 ANY: SUB쿼리로 뽑은 데이터들과 WHERE 조건의 값을 하나씩 다 비교한다. (OR느낌)
(EX: ANY로 뽑은 데이터가 22살과 30살이라면 WHERE절에서 AGE >= 22살 이거나 AGE >= 30살)
🔎 ALL: SUB쿼리로 뽑은 데이터들 중에 대표인 애가 WHERE 조건의 값과 비교한다. (최소값/최대값)
(EX: ALL로 뽑은 데이터가 22살과 30살이라면 WHERE절에서 AGE >= 30살 이상)

#(ADVANCED)예제 1
레벨을 높여서 예제를 하나 실습해보자.
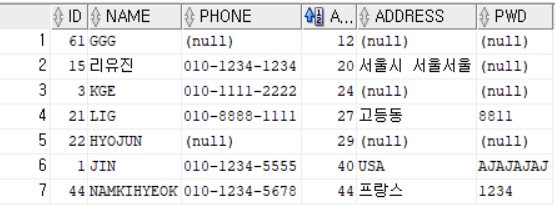
💡 회원의 나이가 30이상인 회원 중에서 가장 나이가 작은 회원(들)을 검색해주세요.
SELECT * FROM MEMBER WHERE AGE = (SELECT MIN(AGE) FROM MEMBER WHERE AGE > 30);⭕ 출력결과:
WHERE에서 AGE랑 비교할 수 있는 것으로는 단일값이 와야 한다.
그렇다면 집계를 해야 하니 SUB쿼리를 이용해서 계산을 하는 방법으로 처리한다.
SUB쿼리에서는 WHERE 조건으로 AGE가 30이상인 것들을 우선 뽑고 그 중에서 SELECT로 MIN(AGE)를 뽑는다.
그러면 SUB쿼리를 통해 나온 값 32가 MAIN쿼리의 WHERE절 AGE와 비교되면서 다음과 같은 결과를 출력한다.

#(ADVANCED)예제 2
이번에는 동갑이 아닌 회원들만 골라서 출력해보자.
💡 동값이 없는 (AGE가 두 개 이상이 없는 회원) 회원들을 검색해주세요.
--방법1
SELECT * FROM MEMBER WHERE AGE IN(SELECT AGE FROM MEMBER GROUP BY AGE HAVING COUNT(AGE) = 1);
--방법2
SELECT * FROM MEMBER WHERE AGE = ANY(SELECT AGE FROM MEMBER GROUP BY AGE HAVING COUNT(AGE) = 1);⭕ 출력결과:
주의해야 할 점1
동갑이 아닌 데이터를 뽑으려면 집계를 할 때 AGE와 COUNT(AGE)로 집계를 해야한다.
동갑이 아니려면 COUNT(AGE) = 1이라는 점을 활용해서 SUB쿼리를 작성한다.
주의해야 할 점2
WHERE절에서 비교할 수 있으려면, 무조건 단일값!!!이 와야 한다.
때문에 값을 여러개 뽑아온 것을 비교하려면 IN 혹은 ANY를 사용해서 비교해보자.
그리고 WHERE절에서 AGE열과 비교할 것이기 때문에 SUB쿼리로 뽑은 컬럼은 AGE 1개만 있어야 한다.
실수로 SUB쿼리에서 (SELECT AGE, COUNT(AGE) FROM MEMBER...)와 같이
2개 이상의 열을 뽑는 실수를 하지 말자. (※값이 너무 많다고 오류남※)
💙 마치며
1.
DISTINCT는 반드시 목록형(열 1개)를 뽑을 때
사용되는 녀석임을 잊지 말자!
2.
ROWNUM과 ORDER BY의 순서를 잘 기억하고,
SUB쿼리를 잘 활용해보자.
3.
ROWNUM을 뽑을 때, 테이블.*을 사용해야
꼬이지 않는다는 것을 잊지말자!

'SQL' 카테고리의 다른 글
| [뉴렉처 6기] Oracle SQL│VIEW│DATE DICTIONARY│PL-SQL (0) | 2023.08.21 |
|---|---|
| [뉴렉처 6기] DATABASE│데이터베이스 모델링(230821) (0) | 2023.08.21 |
| [뉴렉처 6기] Oracle SQL│SELECT문의 작성순서와 실행순서│집계함수 (0) | 2023.08.20 |
| [뉴렉처 6기] Oracle SQL│열을 합치는 JOIN│데이터를 합치는 UNION (0) | 2023.08.20 |
| [뉴렉처 6기] Oracle SQL│연산자│패턴연산│정규식│(230810) (0) | 2023.08.16 |